

Como pessoas desenvolvedoras, algumas vezes iremos nos deparar com tabelas grandes, seja de um sistema legado ou não. Uma estratégia bastante comum é armazenar documentos JSON através de colunas VARCHAR ou NVARCHAR.
A partir do SQL Server 2016 , foram adicionadas as funções JSON, permitindo combinar os conceitos de NoSQL e relacional no mesmo banco de dados.
O objetivo deste artigo é compartilhar algumas dicas que podem ser úteis no seu dia a dia. Devo ressaltar que cada ferramenta resolve um problema específico, então caso sua necessidade seja armazenar documentos com alta performance, o uso de um banco de dados NoSQL pode ser mais adequado.
Construindo e filtrando informações em uma tabela de integração
Vamos imaginar que ficamos responsáveis por extrair e filtrar algumas informações de uma grande tabela de integração. À primeira vista parece algo trivial, mas ao fazer o primeiro SELECT descobrimos que a tabela possui milhares ou até milhões de linhas.
Para nosso experimento, vamos criar uma tabela temporária a partir da declaração:

E em seguida adicionar as duas estruturas JSON abaixo:

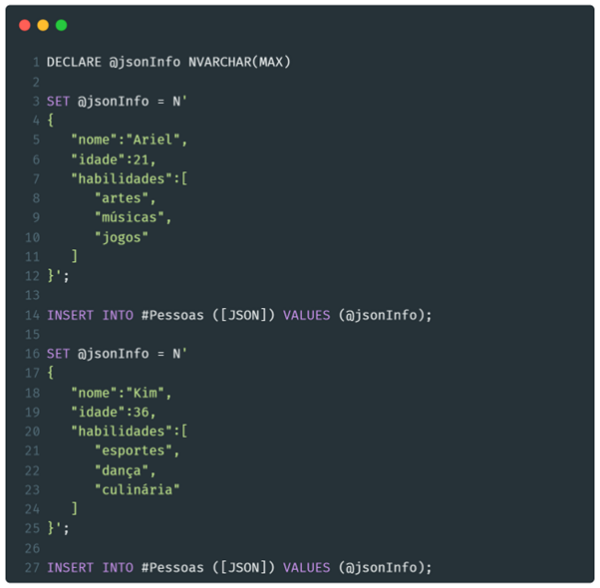
Como resultado teremos duas linhas, representando as pessoas e suas habilidades:

Nosso primeiro objetivo é filtrar todas as pessoas com nome “Kim”. Talvez a primeira ação que venha à mente seja utilizar o operador LIKE, entretanto, essa estratégia não é muito performática para cenários específico, como o nosso exemplo.
A forma mais simples de atingir esse objetivo é utilizar a função JSON_VALUE:

O primeiro parâmetro é a coluna com o documento JSON. Já no segundo parâmetro, devemos informar a propriedade na forma hierárquica que queremos pesquisar.
Dado o exemplo anterior, podemos utilizar a instrução SQL abaixo:

Como resultado, teremos uma única linha com as informações de “Kim”:

Podemos filtrar até mesmo quais pessoas possuem tais habilidades, como por exemplo: “culinária”. Nesse caso, utilizaremos a função OPENJSON, que analisa um texto JSON e retorna os objetos e propriedades como linhas e colunas.
![Imagem com uma instrução SQL filtrando as pessoas que possuem a habilidade de culinária. SELECT * FROM #Pessoas WHERE 'culinária' IN (SELECT value FROM OPENJSON([JSON], '$.habilidades'))](https://www.lambda3.com.br/wp-content/uploads//2023/03/Imagem7.png)

Simples, não?
Agora vamos imaginar que nossa tabela possui milhares ou até mesmo milhões de linhas. Será que a nossa query está rápida suficiente? Apesar de existirem estratégias focadas em otimizações, as vezes precisamos de algo mais simples e rápido para resolver um problema pontual.
Segundo a documentação oficial do MSSQL, os Índices de bancos de dados servem para melhorar o desempenho das operações de filtragem e classificação. Sem índices, o SQL Server precisaria executar uma verificação de tabela completa sempre que você precisar consultar os dados.
Até o momento, não é possível fazer referências diretamente a propriedades em documentos JSON. Portanto, precisamos criar uma “coluna virtual” que retorne os valores para utilizarmos em nosso filtro.
Uma abordagem bastante interessante é a criação de colunas computadas. Por padrão, essas colunas “não existem” e serão calculadas a partir da nossa coluna JSON.

Em seguida, podemos criar nosso índice baseado na coluna “Nome”

Perceba que o MSSQL adicionou uma nova coluna apontando para a propriedade “nome”. Dessa forma, podemos aplicar o filtro diretamente na coluna “nome”, tornando nossa instrução SQL mais simples.

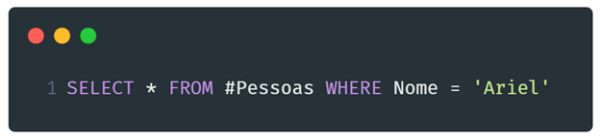

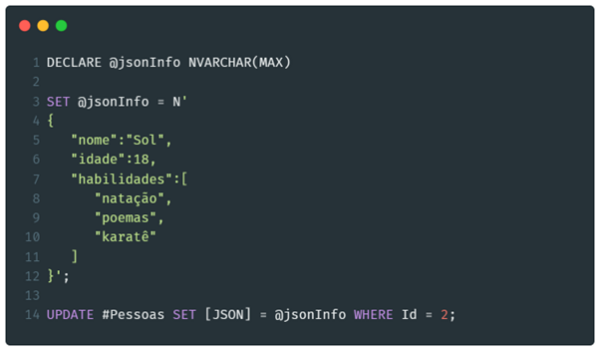
Caso o texto contido na coluna JSON for alterado, a coluna “nome” refletirá o valor atualizado automaticamente.

Conclusão
As funções JSON apresentadas neste artigo podem ser bastante úteis no nosso dia a dia, resolvendo cenários ao qual desejamos mais performance e simplicidade.

Fabio Martinelli
Paulista, desenvolvedor de softwares e baixista nas horas vagas. Sou graduado em Análise e Desenvolvimento de Sistemas, Engenharia de Redes e atualmente sou Microsoft MCP. Acredito na tecnologia como principal ferramenta de transformação, apoiando o ser humano na construção de soluções para os problemas da humanidade.