Objetivo
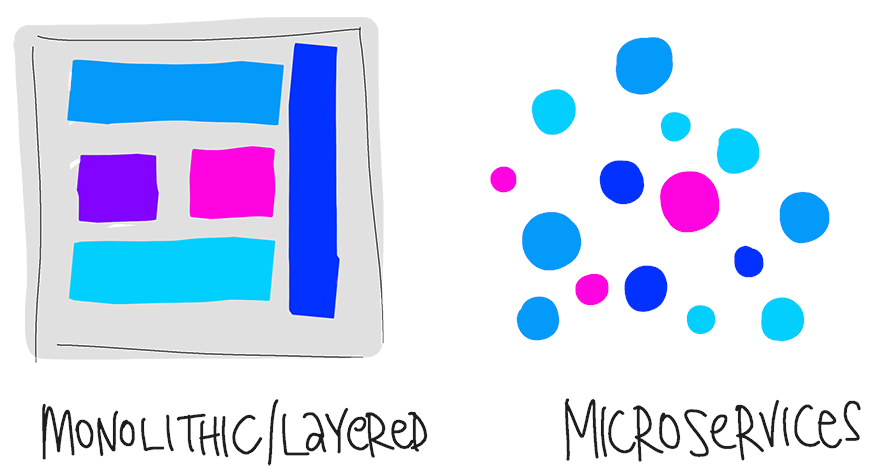
A arquitetura em Microsserviços ganhou popularidade nos últimos anos, porém envolve muito mais do que criar e manter uma solução composta de diversos “micro” serviços.
Em primeiro lugar, quando que uma abordagem distribuída passa a ser mais adequada que uma abordagem monolítica? Que critérios utilizar para isolar e distribuir serviços? Quais os impactos ao adotar uma estratégia distribuída em detrimento da estratégia monolítica?
Para responder as perguntas acima, iremos entender como e por quê aplicar o mindset do Domain Driven Design na refatoração de uma solução monolítica em uma solução distribuída, desfazendo-nos de alguns preconceitos comumente pregados no mercado e tendo ciência dos desafios que essa abordagem trará no desenvolvimento, testes, entrega e manutenção da solução.
Motivação
O Domain Driven Design, ou DDD, consiste num conjunto de princípios e práticas para aproximar a solução técnica ao negócio que ela atende, de uma maneira em que possa ser expandida ao invés de limitada à medida que o entendimento do negócio aumenta. Basicamente, as decisões técnicas estão atreladas à necessidades oriundas do negócio, e não meramente visam “tecnologia por tecnologia” ou “patterns por patterns”, como desenvolvimento voltado a padrões de mercado ou modismos que não estão diretamente relacionados ao problema de negócio.
A arquitetura de Microsserviços é um exemplo de um conceito que pode acabar sendo adotado por ser uma tendência de mercado, sem que o time tenha a devida consciência dos desafios ou mesmo das vantagens que pode trazer à solução.
Em dois artigos anteriores, Desmistificando o DDD e DDD Aplicado: Case Fluxo de produção de equipamentos por demanda, eu explico alguns dos princípios do DDD e como eles podem afetar estratégias de negócio e software.
Nesse artigo mostrarei como o mindset do DDD pode ser usado para modelar microsserviços de uma maneira alinhada com o negócio, ou mesmo questionar se microsserviços é a escolha mais adequada para o cenário em questão.
DDD e Microsserviços — O melhor dos dois mundos
Quando unimos os princípios do DDD com a arquitetura de Microsserviços, permitimos o gerenciamento descentralizado de acordo com o contexto de negócio. Determinado contexto pode demandar necessidades específicas, tanto no desenvolvimento (linguagem, paradigma, plataforma) quanto na infra (bare metal vs virtualização, número de instâncias). Quando o modelo está maduro, permite entregas velozes, ambiente resiliente e elasticidade.
Porém, a falha na implementação dos princípios básicos pode transformar o que seria uma solução de microsserviços em um monolito composto por serviços altamente acoplados — na prática, o que antes era um ponto de falha centralizado e um único serviço para versionar, entregar e sustentar, se transforma em dezenas ou centenas.
Segundo a Conway’s Law [1] -“Any organization that designs a system (…) will produce a design whose structure is a copy of the organization’s communication structure”, isto é, a implementação da solução tende a refletir a estrutura empresarial, o que muitas vezes não é o mais adequado para tirar proveito da flexibilidade que a arquitetura de microsserviços oferece. Se isso acontecer, pode-se imaginar que a organização dos microsserviços irá refletir a organização dos times, por exemplo, front-end, regras de negócios, infraestrutura, etc.
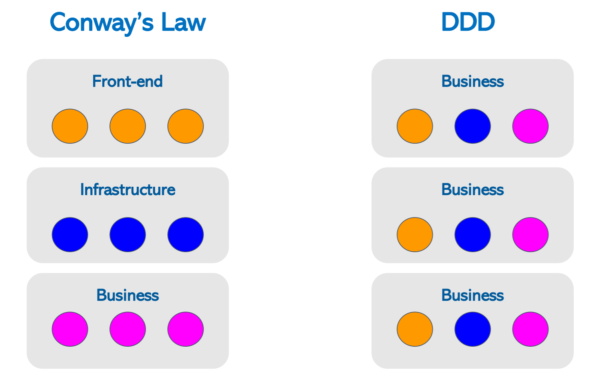
Conway’s Law vs DDD
Em contrapartida, aplicando princípios do DDD, os serviços podem ser organizados de acordo com o contexto que eles atendem — por exemplo, serviços relacionados são publicados no mesmo cluster para diminuir o delay entre as operações.
Para exemplificar a raiz de alguns dos desafios da arquitetura em microsserviços, iremos demonstrar nos tópicos a seguir um cenário em que um dos módulos de uma solução monolítica foi isolado, e analisaremos os impactos diretos dessa refatoração sob a ótica do DDD.
Cenário
A aplicação é um portal de troca de pontos por produtos, semelhante a um e-commerce. O usuário autenticado navega em um Portal Web, seleciona produtos de acordo com seu saldo de pontos e então solicita a troca. O sistema de Carrinho de Compras efetua a transação e retorna para o usuário o protocolo de seu pedido, enquanto dispara o fluxo de logística. O usuário receberá em até 24h um e-mail com a confirmação do pedido e data de entrega.
Mapa de Contexto
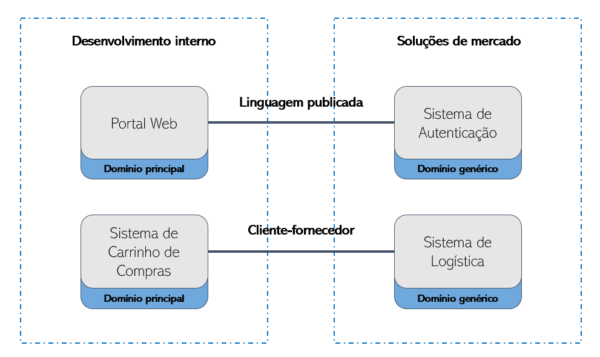
Mapa de Contexto
Nesse cenário, o Portal Web e o sistema de Carrinho de Compras foram desenvolvidos internamente, com integrações para um sistema de autenticação de mercado (Azure Active Directory, por exemplo) e um sistema de logística externo e customizado.
Transação de troca de pontos por produtos
O principal fluxo do contexto pode ser retratado da forma abaixo:
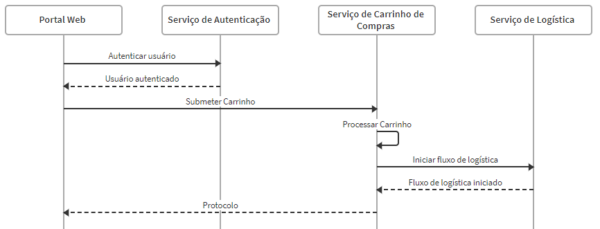
Fluxo principal
Se destacássemos a transação de submissão do Carrinho de Compras já criado, teríamos um fluxo semelhante ao mostrado abaixo:
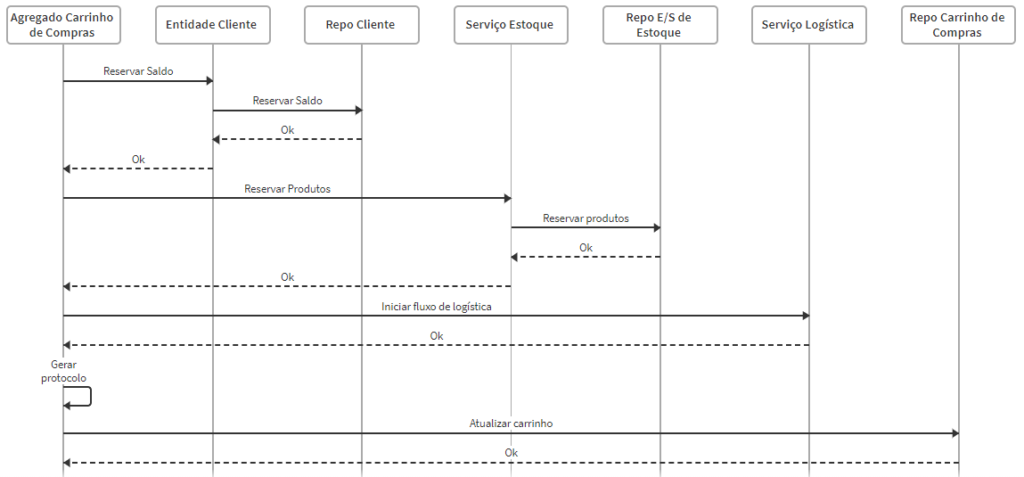
Fluxo de submissão do carrinho de compras
O serviço interno de logística consiste em um adaptador que traduz o objeto do carrinho para o objeto a ser enviado para o sistema externo de Logística. Os repositórios do Carrinho de Compras, Cliente e de E/S de Estoque estão dentro da unidade de trabalho do Carrinho de Compras, e o fluxo está contido em uma transação de banco de dados. Caso algum problema ocorra, como um produto subitamente indisponível ou falha na comunicação com o Sistema de Logística, a transação será revertida. Caso contrário, será confirmada.
Building Blocks
Para efeitos de ilustração, imaginem que o sistema de Carrinho de Compras foi organizado contemplando os seguintes componentes e building blocks:
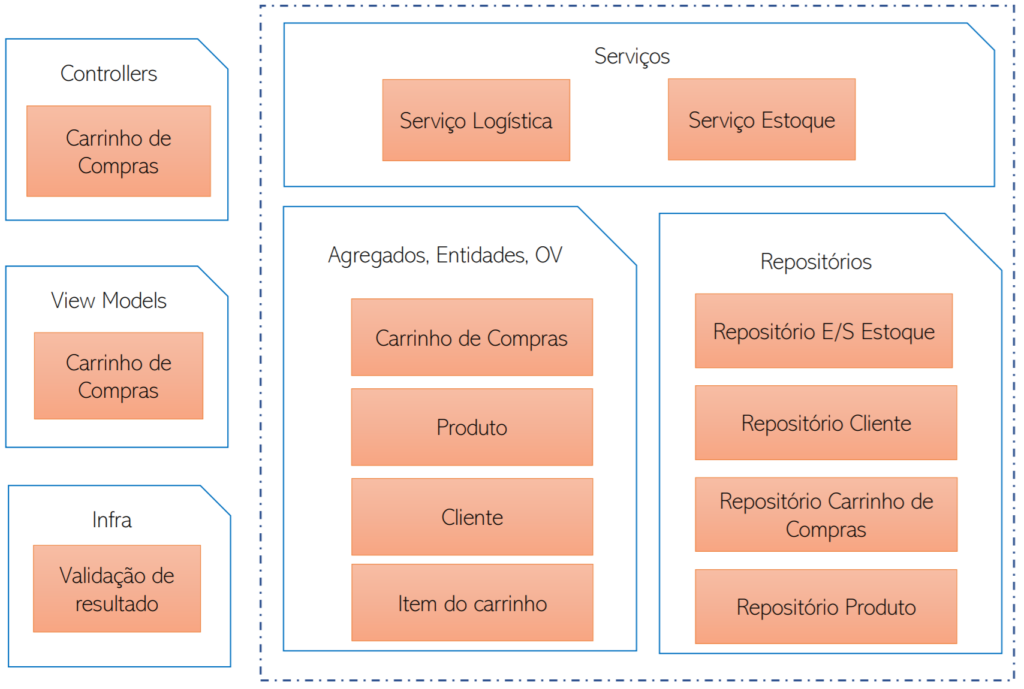
Building blocks do Serviço de Carrinho de Compras
Vantagens na abordagem monolítica
É muito comum ouvir associações entre a abordagem monolítica com projetos legados cheios de débitos técnicos, porém é incorreto supor que uma coisa seja consequência da outra. Uma solução nova desenvolvida em microsserviços pode também conter débitos técnicos críticos e limitações arquiteturais.
Uma aplicação monolítica não é necessariamente ruim. Pode ser bem implementada e resolver eficientemente o problema proposto se a solução realmente puder ser considerada como uma unidade, inclusive refletir princípios do DDD, se for o caso.
Comparando uma aplicação monolítica em camadas desenvolvida de maneira consistente com uma solução equivalente distribuída em microsserviços, podemos notar vantagens em diversos aspectos:
- Desenvolvimento e debug: Preparar um ambiente de desenvolvimento é mais simples. Falhas de integração entre camadas resultam em erros de compilação, que podem ser rapidamente percebidos e corrigidos. O processo de debug permite “navegar” entre as diferentes camadas envolvidas em cada transação, tornando possível realizar testes end-to-end sem grandes dificuldades;
- Testes de integração: Normalmente a aplicação se conecta a poucas bases de dados, sendo assim relativamente simples trabalhar com massas de dados descartáveis;
- Integridade de dados: O banco de dados centralizado possibilita um maior controle sobre a integridade de dados. Eliminar os rastros de uma transação mal sucedida é praticamente imediato;
- Velocidade de execução: A execução em um único processo garante maior velocidade. O delay entre as diferentes etapas de execução de uma transação raramente é um problema;
- Construção e Entrega contínuas: O esforço operacional para manter um único repositório e esteira de build/deploy é baixo.
Quando a necessidade de isolar um dos módulos surge
Em algum momento do ciclo de vida do projeto, o time pode chegar a conclusão de que um determinado módulo precisa ser isolado e ter um ciclo de vida próprio. Algumas das razões podem ser:
- Demanda diferenciada do módulo comparando com a solução como um todo — há um número consideravelmente maior de consumidores para recursos específicos desse módulo ao invés da solução completa;
- Dependência de recursos distintos de hardware ou software de modo a ser mais adequado o gerenciamento apartado, por exemplo a execução em um servidor físico e não virtual para maior performance;
- Um novo produto será construído a partir de determinado módulo por necessidades de negócio;
Se houver uma razão concreta para a separação de um ou mais módulos, é importante entender o impacto de refatoração e as preocupações que passam a surgir quando se adota uma estratégia distribuída.
Refatorando a solução
Para ilustrar, imaginem que o módulo de estoque será transformado em um serviço isolado.
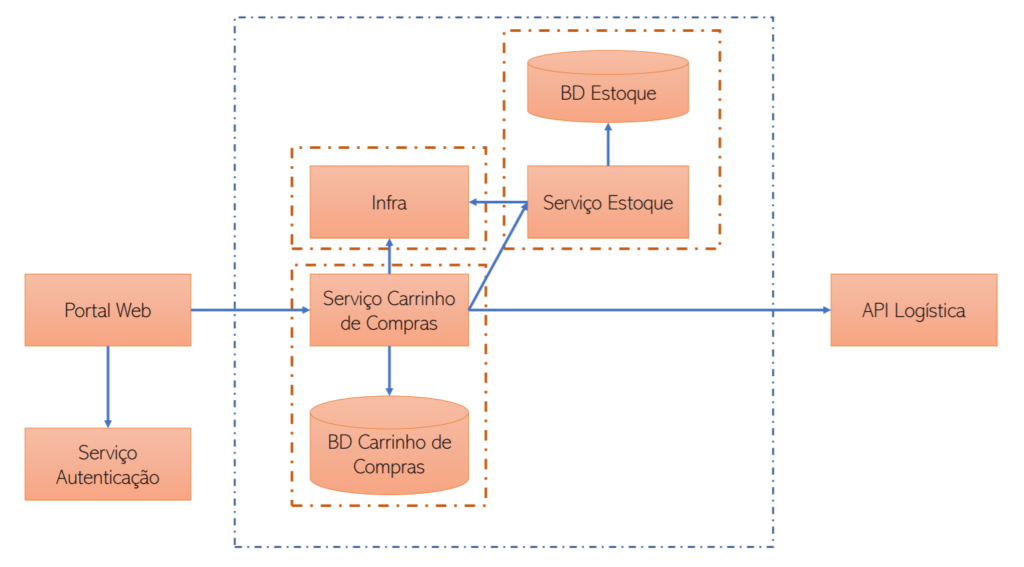
Isolamento do Serviço de Estoque
Os impactos diretos poderiam ser:
- Isolamento do código compartilhado para que ambos os serviços (Carrinho de Compras e Estoque) consumam as funcionalidades comuns a ambos de maneira centralizada;
- Remoção ou adaptação do código referente a estoque no Serviço de Carrinho de Compras;
- Separação da base de dados de estoque;
Núcleo compartilhado
Será necessário decidir como os sistemas lidarão com o código compartilhado — normalmente de infraestrutura ou o famoso “utils” — funcionalidades genéricas que foram abstraídas de forma a serem reaproveitadas para aumentar a velocidade no desenvolvimento.
A primeira opção é duplicar esses códigos no serviço novo que contemplará o módulo de estoque. A segunda, utilizada nesse exemplo, é isolar o código compartilhado em uma biblioteca e distribuí-la em ambos os serviços. A terceira é disponibilizar a funcionalidade via serviço, se fizer sentido.
Duplicar o código pode soar como um antipattern, porém é interessante quando a funcionalidade pode crescer com velocidades e necessidades diferentes entre os consumidores.
Se o código realmente for genérico, pode-se distribuí-lo como componente. Nesse caso ele terá sua esteira de entrega para algum repositório de componentes adequado (Nexus, Package Management, etc). O gerenciamento sólido de versões é fundamental (por exemplo, {Major}.{Minor}.{Patch}, incrementando o Major quando houver quebra de contrato, incrementando o Minor para funcionalidades novas e correções, e associar o número Patch com o ID do artefato para garantir a unicidade e rastreamento). Além disso, para garantir a compatibilidade, ao publicar uma versão nova é necessário manter as anteriores disponíveis enquanto houverem consumidores.
E há cenários em que o código compartilhado deveria ser distribuído via serviço, e não como componente. Se a funcionalidade contida no componente precisa estar 100% atualizada para todos os consumidores em tempo real, como o que ocorre com regras de negócio, ao modificar o componente será necessário realizar a atualização e redeploy de cada um de seus consumidores, gerando um esforço operacional e um risco. A melhor alternativa seria disponibilizar esses recursos via serviço, para garantir que os consumidores sempre tenham acesso à versão mais recente disponível.
Serviço de Estoque
Após o isolamento do módulo de infra, é feito o isolamento do módulo de estoque e também do seu banco de dados. Conforme a figura abaixo, no Serviço de Estoque ficam só os componentes relevantes ao sub-domínio de estoque.
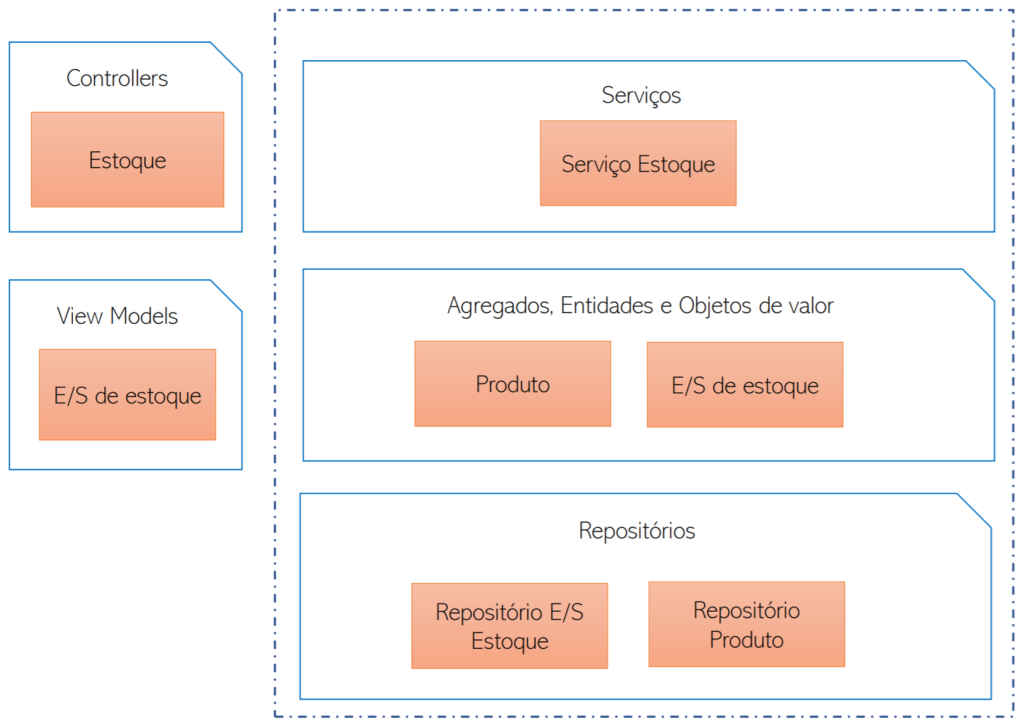
Building Blocks do Serviço de Estoque
No Serviço de Carrinho de Compras parte do código de estoque foi removida, porém alguns componentes continuam — por exemplo o serviço de estoque, que ao invés da implementação concreta será um adapter de comunicação com o novo Serviço de Estoque. A entidade Produto continua existindo, porém apenas com o conteúdo relevante para esse contexto.
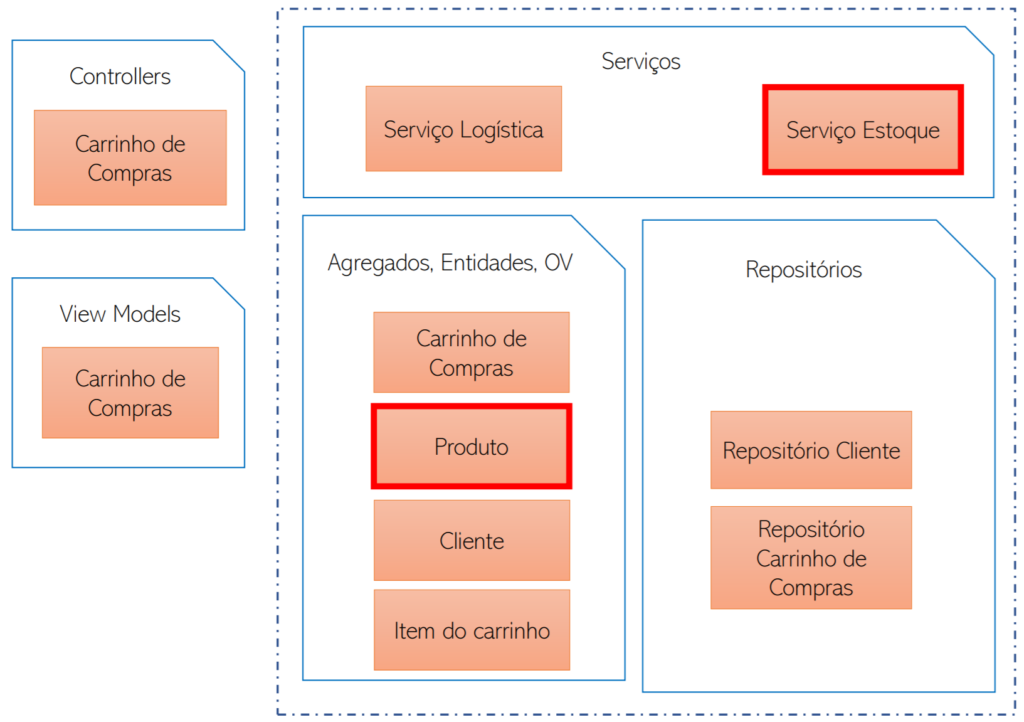
Building Blocks do Serviço de Carrinho de Compras
Impacto na transação de resgate de pontos
A transação de resgate de pontos depende que os produtos sejam reservados no estoque para que seja concluída. O usuário aguarda a conclusão da transação com seu número de protocolo e espera que isso aconteça em poucos instantes.
O que acontece quando a comunicação com o serviço de Estoque falha, seja por bug ou por problemas de conexão (timeout, permissões de rede, etc)?
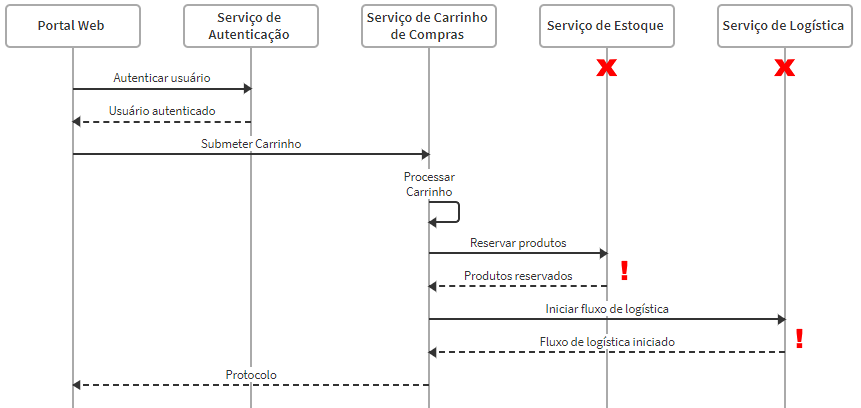
Fluxo principal refatorado
Nesse cenário, alguma política de Retry adequada precisa ser implementada para comunicação com o serviço de Estoque. Uma requisição mal formada ou recusada não necessita Retry, porém um timeout por falha de comunicação pode permitir um número determinado de tentativas mantendo os princípios de circuit-break [2].
Caso mesmo com o Retry a comunicação não seja bem sucedida, o rollback lógico deve ser realizado, provavelmente com uma estratégia SAGA [3] já que as bases de dados estão distribuídas.
Impacto no desenvolvimento e testes
Imagine que agora a manutenção do Serviço de Carrinho de Compras e do Serviço de Estoque seja realizada por times diferentes. Falhas de compatibilidade não são mais percebidas em tempo de compilação! Será necessário usar alguma estratégia de testes de contrato para que a compatibilidade de comunicação seja garantida.
O teste de integração depende não só de uma massa de dados exclusiva e descartável para o Serviço de Carrinho de Compras mas agora para o Serviço de Estoque também. O endpoint do Serviço de Estoque utilizado para o teste de integração do Serviço de Carrinho de Compras precisa estar acessível exclusivamente ao Serviço de Carrinho de Compras, já que uma alteração paralela na massa de dados pode comprometer a confiabilidade do teste de integração.
A latência entre a comunicação do Serviço de Carrinho de Compras e do Serviço de Estoque é mais um ponto de atenção que não existia na abordagem monolítica. Quando as transações são executadas em um único processo a latência normalmente não é levada em consideração. Porém ao distribuir etapas da mesma transação em serviços isolados, muitas vezes a latência só será percebida no ambiente produtivo, não em tempo de desenvolvimento, até mesmo pela dificuldade em realizar testes integrados.
Além da latência, certos riscos que não são óbvios no ambiente de desenvolvimento precisam ser antecipados, como falha de comunicação devido a permissionamento ou indisponibilidade.
Outros pontos de atenção que surgem quando se migra de uma solução monolítica para em microsserviços são descritos no paper “As 8 falácias da computação distribuída” [4].
Considerações finais
O mindset do Domain Driven Design pode ser aplicado tanto em soluções monolíticas quanto em microsserviços, afetando as decisões de design (como os objetos e eventos serão modelados), software (tecnologia, plataformas e dependências) e hardware (que recursos serão utilizados e como a solução será distribuída).
Soluções monolíticas atendem eficientemente grande parte dos cenários de mercado.
A utilização de componentes/bibliotecas internos traz desafios de versionamento, distribuição e compatibilidade. Se os consumidores precisam obrigatoriamente ter acesso à última versão, disponibilize a funcionalidade via serviço e não via componente. Se os consumidores possuem necessidades distintas, replique o código em cada consumidor para maior flexibilidade de alteração ao invés de centralizar em um componente.
A distribuição de funcionalidades em serviços implica em desafios no gerenciamento, desenvolvimento, testes e operações. Não distribua recursos que poderiam estar contidos no mesmo serviço a menos que haja uma justificativa concreta.
As justificativas e estratégias de distribuição trarão melhores resultados se estiverem alinhadas com o negócio, e não com padrões corporativos (Conway’s Law) ou patterns e modismos mal colocados.
Referências
- [1] Conway’s Law (http://www.melconway.com/Home/Conways_Law.html)
- [2] Circuit Break (https://techblog.constantcontact.com/software-development/circuit-breakers-and-microservices/)
- [3] Padrão SAGA (https://developers.redhat.com/blog/2018/10/01/patterns-for-distributed-transactions-within-a-microservices-architecture/)
- [4] As 8 falácias da computação distribuída: (http://nighthacks.com/jag/res/Fallacies.html)
Graziella Bonizi